


Dr. Noriaki Kano's Model
Dr. Noriaki Kano's Model
Characterizing responses to product features since 1984

How do we decide what features we should add to our roadmaps? How can we determine how our decision to invest in a feature, or leave it out of our product, will impact user satisfaction?
That is where the Kano model comes in. It gives a structured and reliable way of categorizing how users will respond to features that can inform roadmap priorities.
Quick overview…
KANO et al., Attractive Quality and Must-Be Quality, 1984
Daniel Zacarias, The Complete Guide to the Kano Model, 2016
Dr. Noriaki Kano first published his model of customer satisfaction in 1984. Years later, Zacarias wrote the Folding Burritos article that has become the go-to how-to article on Kano surveys. These two articles are a good starting point for learning the Kano model.
The Theory
The foundation of the Kano model is that you can characterize a customer’s reaction to a feature by mapping two dimensions: satisfaction (e.g., how satisfied a customer is with your product) & functionality (e.g., how much you have invested in the functionality of the feature in question).
Kano proposed that there are a set of categorically distinct patterns that describe this satisfaction*functionality relationship for any feature. These include:
Attractive (also called delighters, exciters) - These are features people do not expect but are delighted by. In other words, their absence does not negatively impact satisfaction, but their presence increases it.
Performance (one-dimensional, linear) - Features that have a linear relationship with satisfaction; as you improve these features, satisfaction increases in kind.
Must-have (must-be, threshold, basic, expectations, table-stakes) - These are features that people expect to have; their presence does not increase satisfaction, and their absence causes dissatisfaction.
Indifferent (unimportant) - People do not care about these features. Investing in them or leaving them out will not impact product satisfaction.
Reverse (undesired) - Features that people do not want and will cause dissatisfaction if implemented. Often left out of descriptions of the method, but examples exist.

You will notice that the uniqueness of the Kano model comes from considering the impact of the absence of a feature. For this reason, we use Kano studies to prioritize which features to include in, or leave off, a product roadmap.
The Questionnaire
The articles above provide a detailed explanation of the questionnaire and scoring techniques; so I’ll give a basic overview.
The questionnaire presents each feature individually and asks users two questions:
How do you feel if you had this feature?
I like it / I expect it / I am neutral / I can tolerate it / I dislike it
How do you feel if you did not have this feature?
I like it / I expect it / I am neutral / I can tolerate it / I dislike it1
Using the responses to these questions, we can categorize features into one of the Kano model categories.
Getting the most out of Kano in practice
Now that you know the basics, let’s review Kano in practice. Here are some considerations, quirks, and observations in the form of Q&A:
How do you pronounce “Kano?”
Like ‘Kah-no.’ ‘Can-oh’ sounds sort of close if mumbled, but never ‘Kane-no’, or ‘Kane-oh.’
In what situations does Kano work best?
Imagine you have a long list of potential product features. They might come from a competitive evaluation (you find features other products have that yours doesn’t), or some exploratory research/design thinking activities (you generate new feature ideas based on an evaluation of unmet user needs). In either of these scenarios, the proposed list of features is usually greater than what the team can deliver. The Kano model helps cull the herd by identifying how users would respond to each proposed feature. The results help product teams prioritize only those features that are Must-haves or would have a positive impact on customer satisfaction.
When would you use Kano vs. MaxDiff?
Those familiar with MaxDiff might notice similarities and wonder what sets Kano apart. Here are three key differences:
Theoretically - Kano’s non-unidimensional scale allows you to distinguish between Must-haves and Attractive features. You should value running a Kano study if you value this theoretical distinction.
Logistically - Kano studies tend to be easier and somewhat quicker to conduct than MaxDiff analyses.
In Practice - There is no reason not to run both2. You can use Kano as an exploratory first step to identify which of the proposed features should be included in a product roadmap, then run a MaxDiff to determine their order and level of investment.
How do you present features so that they are understood by participants?
Written descriptions combined with a static visual mockup work best. Some suggest making an interactive prototype, but this has two downsides. First, participants get caught up on small details of your prototype and react to your execution, not the concept. Second, you don't want to waste design resources creating interactive prototypes of features you might never make.
As for the written descriptions, you should test them before launching the questionnaire and ensure that any scenarios you include reflect how users engage with your product.
How many features should we test?
The consensus seems to be 10-15 but no more than 20. The consistency of the Kano questionnaire should make responding to each feature relatively easy, but after reading through twenty features participants will be fatigued and disinterested3.
What sample size should I use?
In the past, I have suggested at least 50. That is similar to Jeff Sauro of MeasuringU’s suggestion of n= 50-300. Sauro’s rationale is that it achieves a 5-9% margin of error, good for most cases.
Some attest that you can run Kano with samples of as few as 12. Note that Kano results at such a small sample size will be extremely inconsistent.
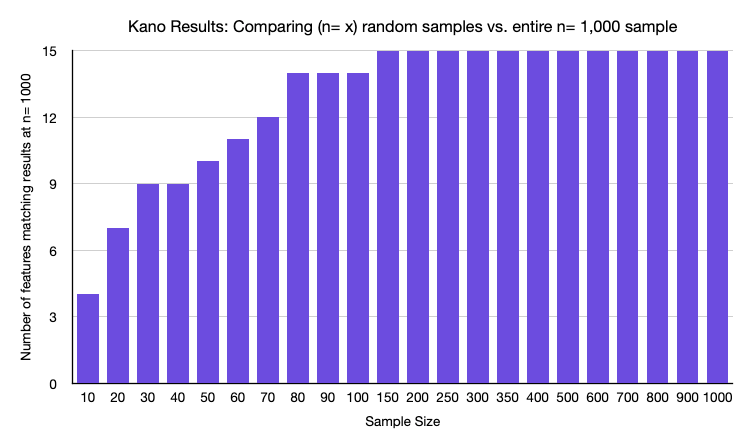
To demonstrate this, I took a Kano survey of fifteen features with n= 1,000, drew random samples of various sizes, and compared the result (e.g., was a feature “Attractive,” “Must-have,” etc.) of n= x to n= 1,000. Through this exercise, we can observe when Kano results start to stabilize.
The results (below) showed that at n= 10, only 4 out of the 15 features were in the same category as the n= 1,000 results. We would draw the wrong conclusion about the Kano category of most of our features at that sample size. We reach 7 out of 15 at n= 20, which is better, but I’m sure most of us do not want to make decisions on data that are only ‘right’ half the time. The data did not become consistent until about n= 70, where 12 of the 15 features (80%) were the same as the n= 1,000 sample. At n= 150, you see a ceiling effect, where the result for all 15 features in the test had the same category result as the entire n= 1,000 sample.
Can we skip the survey? Can we run a workshop using data from past research and analytics to infer Kano categories?
No. Kano was designed to be a research method with users, not a collaborative workshop/scoring session with the product team. If you want to do that you should choose a different roadmap prioritization technique.
What is something more people should consider?
Two I strongly recommend:
Different types of users - Different user groups react differently to the same feature. If you have different personas, recruit at least n= 50 of each in your sample. If you’re testing “innovative” new features, you should capture a measure of tech adoption. Analyze for differences in these groups. You will likely find that some features have mass appeal and others resonate with a smaller group; it is important to know both.
Testing to remove - Many digital products suffer from feature bloat; new bells and whistles have been added over release cycles, causing the product to become large and increasingly complex. By identifying low-use features through analytics, then determining which are Indifferent through a Kano study, a product team could decide to fix feature bloat by removing what doesn’t deliver value.
Why are most of my feature ideas “Indifferent?” What’s wrong?
It’s funny, I get asked this all the time. When you run a Kano study you’re likely to find that many to most of the things you test are “Indifferent.” This is a feature, not a bug. Most features we come up with are not that appealing to our users. Kano results give us a reality check.
Does the response scale seem ‘funny’ to you?
Two responses: 1) Read the Zacarias article for alternate phrasings, and 2) You might mistake it for a continuous scale when conceptually it is categorical (or ordinal in the eyes of the product owner who wants a more positive reaction from users).
How does prioritization work in practice?
That is where the rubber meets the road with Kano. The general guidance is to prioritize Must-haves, then Performance, then Attractive.
The problem with this convention is the decay of delight. Features that were once Attractive become Must-haves (imagine hot water or WiFi in your hotel room; both were delightful to guests at one point, but now you would be disappointed to be missing either). Some product teams find themselves in a situation where they are always delivering on Must-haves, and fighting the competition to have the best Performance features, but never making room for “delighters” until they become a requirement.
If you find this is the case with your product, it might be time to rethink your positioning. With a more narrow offering, you should be able to make room for Attractive features on top of delivering Must-haves and good Performance features. Your product offering might not be as broad or impressive, but you will be able to differentiate from the competition and win your narrower space.
There is no perfect method for product roadmap prioritization, but Kano gives us a model for assessing user reactions to new features systematically and reliably. With the Kano model, you will be armed with the information you need to advocate for user value in roadmap priority discussions that might otherwise rely solely on business value and technical feasibility.
Until next month.
Cheers,
Thomas
Extra Reading: Reliability and Validity…
Mikulic & Prebezac, A critical review of techniques for classifying quality attributes in the Kano Model, 2011
Reliability and validity are important to any research method. Mikulic & Prebezac authored an extensive review of Kano and similar methods. If you read a third article on Kano I recommend this one. Here are a few highlights:
Kano questions should be worded in terms of the presence/absence of the feature & its benefits. Phrasing questions about high vs. low performance decreases the method’s reliability.
Reading between the lines you’ll notice that the Kano model is judged by its face, discriminative, and content validity but not its predictive validity. This makes sense; empirically testing the predictive ability of the model on a real product would be messy OR demand a level of control that might hinder product iteration and improvement outside of the feature in question. If you are looking for an issue with the Kano model, it is predictive validity, but you’d be hard-pressed to find better alternatives.
The traditional Kano approach (as described above) has validity for categorically assessing customer reactions, high reliability, and is generally the most useful of the alternatives assessed.
For a detailed overview of alternate phrasing of the questions and response items see the Folding Burritos article
Assuming you have the time and resources
To my knowledge, this suggestion has not been empirically tested